
Common Expression Language (CEL) to język wyrażeń ogólnego przeznaczenia zaprojektowany tak, aby był szybki, przenośny i bezpieczny w użyciu. Możesz używać CEL samodzielnie lub osadzać go w większym produkcie. CEL doskonale sprawdza się w wielu zastosowaniach, od kierowania zdalnymi wywołaniami procedur (RPC) po definiowanie zasad bezpieczeństwa. CEL jest rozszerzalny, niezależny od platformy i zoptymalizowany pod kątem przepływów pracy typu „skompiluj raz, oceń wiele razy”.
CEL został zaprojektowany specjalnie z myślą o bezpiecznym wykonywaniu kodu użytkownika. Chociaż bezkrytyczne wywoływanie funkcji eval() w kodzie Pythona użytkownika jest niebezpieczne, możesz bezpiecznie wykonać kod CEL użytkownika. CEL zapobiega działaniom, które mogłyby obniżyć wydajność, dlatego ocenia bezpiecznie w nanosekundach lub mikrosekundach. Szybkość i bezpieczeństwo CEL sprawiają, że jest to idealne rozwiązanie w przypadku aplikacji o krytycznym znaczeniu dla wydajności.
CEL ocenia wyrażenia podobne do funkcji jednowierszowych lub wyrażeń lambda. Wyrażenia CEL są zwykle używane do podejmowania decyzji logicznych, ale możesz ich też używać do tworzenia bardziej złożonych obiektów, takich jak wiadomości JSON lub wiadomości bufora protokołu.
Dlaczego CEL?
Wiele usług i aplikacji ocenia deklaratywne konfiguracje. Na przykład kontrola dostępu oparta na rolach (RBAC) to deklaratywna konfiguracja, która na podstawie roli użytkownika i zbioru użytkowników podejmuje decyzję o dostępie. Konfiguracje deklaratywne wystarczają w większości przypadków, ale czasami potrzebujesz większej mocy wyrażania. Właśnie dlatego powstał język CEL.
Przykładem rozszerzenia konfiguracji deklaratywnej za pomocą CEL mogą być możliwości usługi Google Cloud Identity and Access Management (IAM). RBAC jest powszechnie stosowany, ale uprawnienia oferują wyrażenia CEL, które pozwalają użytkownikom dodatkowo ograniczyć zakres przyznania opartego na rolach zgodnie z właściwościami wiadomości protokołu żądania lub zasobów, do których uzyskuje się dostęp. Opisywanie takich warunków za pomocą modelu danych spowodowałoby powstanie skomplikowanego interfejsu API, z którego trudno byłoby korzystać. Zamiast tego używanie CEL z kontrolą dostępu opartą na atrybutach (ABAC) jest wyrazistym i zaawansowanym rozszerzeniem RBAC.
Podstawowe pojęcia CEL
W języku CEL wyrażenie jest kompilowane w środowisku. Etap kompilacji tworzy drzewo składni abstrakcyjnej (AST) w formacie bufora protokołu. Skompilowane wyrażenia są przechowywane do wykorzystania w przyszłości, aby zapewnić jak najszybsze obliczanie. Pojedyncze skompilowane wyrażenie można obliczać na podstawie wielu różnych danych wejściowych.
Przyjrzyjmy się bliżej niektórym z tych pojęć.
Wyrażenia
Wyrażenia są pisane przez użytkowników. Wyrażenia są podobne do jednowierszowych treści funkcji lub wyrażeń lambda. Sygnatura funkcji, która deklaruje dane wejściowe, jest zapisywana poza wyrażeniem CEL, a biblioteka funkcji dostępnych w CEL jest importowana automatycznie.
Na przykład to wyrażenie CEL przyjmuje obiekt żądania, a żądanie zawiera token claims. Wyrażenie zwraca wartość logiczną, która wskazuje, czy token claims jest nadal ważny.
Przykładowe wyrażenie CEL do uwierzytelniania tokena roszczeń
// Check whether a JSON Web Token has expired by inspecting the 'exp' claim.
//
// Args:
// claims - authentication claims.
// now - timestamp indicating the current system time.
// Returns: true if the token has expired.
//
timestamp(claims["exp"]) < now
Użytkownicy definiują wyrażenie CEL, a usługi i aplikacje określają środowisko, w którym jest ono uruchamiane.
Środowiska
Środowiska są definiowane przez usługi. Usługi i aplikacje, które osadzają CEL, deklarują środowisko wyrażeń. Środowisko to zbiór zmiennych i funkcji, których można używać w wyrażeniach CEL.
Na przykład ten kod textproto deklaruje środowisko zawierające zmienne request i now za pomocą komunikatu CompileRequest z usługi CEL.
Przykładowa deklaracja środowiska CEL
# Format: $SOURCE_PATH/service.proto#CompileRequest
declarations {
name: "request"
ident {
type { message_type: "google.rpc.context.AttributeContext.Request" }
}
}
declarations {
name: "now"
ident {
type { well_known: "TIMESTAMP" }
}
}
Deklaracje oparte na protokole są używane przez moduł sprawdzania typów CEL, aby zapewnić, że wszystkie odwołania do identyfikatorów i funkcji w wyrażeniu są zadeklarowane i używane prawidłowo.
Etapy przetwarzania wyrażeń
Wyrażenia CEL są przetwarzane w 3 fazach:
- Analizuj
- Czek
- Oceń
Najczęstszy sposób użycia CEL polega na analizowaniu i sprawdzaniu wyrażeń w czasie konfiguracji, przechowywaniu drzewa składni abstrakcyjnej (AST), a następnie wielokrotnym pobieraniu i ocenianiu drzewa AST w czasie wykonywania.
Ilustracja faz przetwarzania CEL
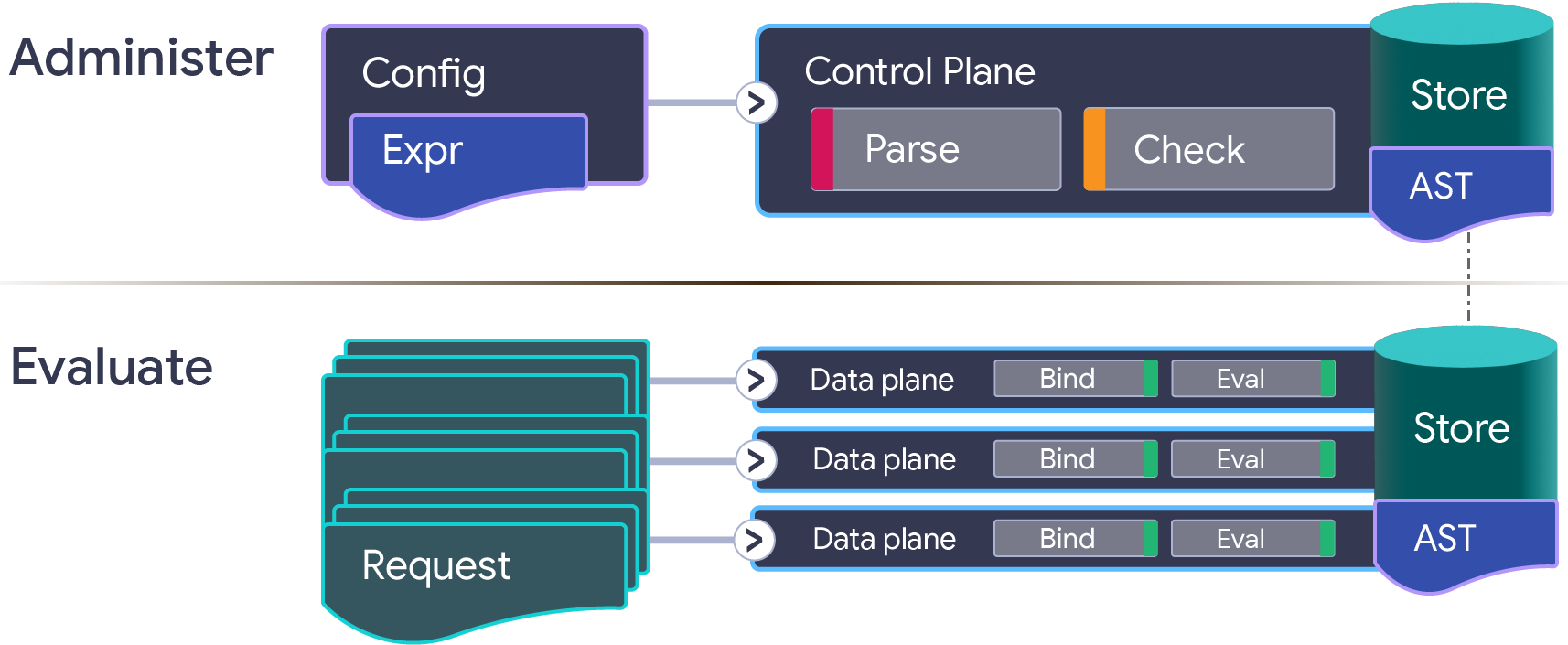
Wyrażenie CEL jest analizowane z postaci czytelnej dla człowieka do postaci AST za pomocą analizatora leksykalnego i składniowego ANTLR. Faza analizy składniowej generuje AST oparty na protokole, w którym każdy węzeł Expr zawiera identyfikator liczbowy używany do indeksowania metadanych wygenerowanych podczas analizy składniowej i sprawdzania. Plik syntax.proto, który powstaje podczas analizowania, reprezentuje abstrakcyjną formę tego, co zostało wpisane w ciągu znaków wyrażenia.
Po przeanalizowaniu wyrażenia jest ono sprawdzane pod kątem typu w środowisku, aby upewnić się, że wszystkie identyfikatory zmiennych i funkcji w wyrażeniu zostały zadeklarowane i są używane prawidłowo. Sprawdzanie typów generuje plik checked.proto, który zawiera metadane dotyczące typów, zmiennych i funkcji, co może znacznie zwiększyć wydajność oceny.
Na koniec, po przeanalizowaniu i sprawdzeniu wyrażenia, następuje ocena zapisanego drzewa składni abstrakcyjnej.
Oceniający CEL potrzebuje 3 rzeczy:
- Wiązania funkcji dla wszystkich rozszerzeń niestandardowych
- Powiązania zmiennych
- AST do oceny
Powiązania funkcji i zmiennych powinny być zgodne z powiązaniami używanymi do kompilowania drzewa składni abstrakcyjnej. Każde z tych danych wejściowych może być ponownie użyte w wielu ocenach, np. drzewo składniowe może być oceniane w wielu zestawach powiązań zmiennych, te same zmienne mogą być używane w wielu drzewach składniowych, a powiązania funkcji mogą być używane przez cały czas trwania procesu (jest to częsty przypadek).